Branding & frontend

Background
I was doing work at a stealth product at the time that used the common strategy of:
- Embed documents using OpenAI's
text-embedding-ada-002. - Store them in a vector database.
- Retrieve the top5 documents from a vector database.
- Use the retrieved documents as part of a prompt to a LLM.
The product was not performing as we expected and, after analyzing it, we concluded the main problem was the quality of the retrieved results from the vector database. After trying a bunch of techniques (e.g. HyDE), I became convinced I could build a better retrieval layer myself.
On a reduced MS MARCO benchmark, Memora’s retrieval stack achieved ~71% higher MRR@10 than our baseline “vector-DB + ada-002” setup, while maintaining p90 latency under 400ms at around 100k documents.
Tech report
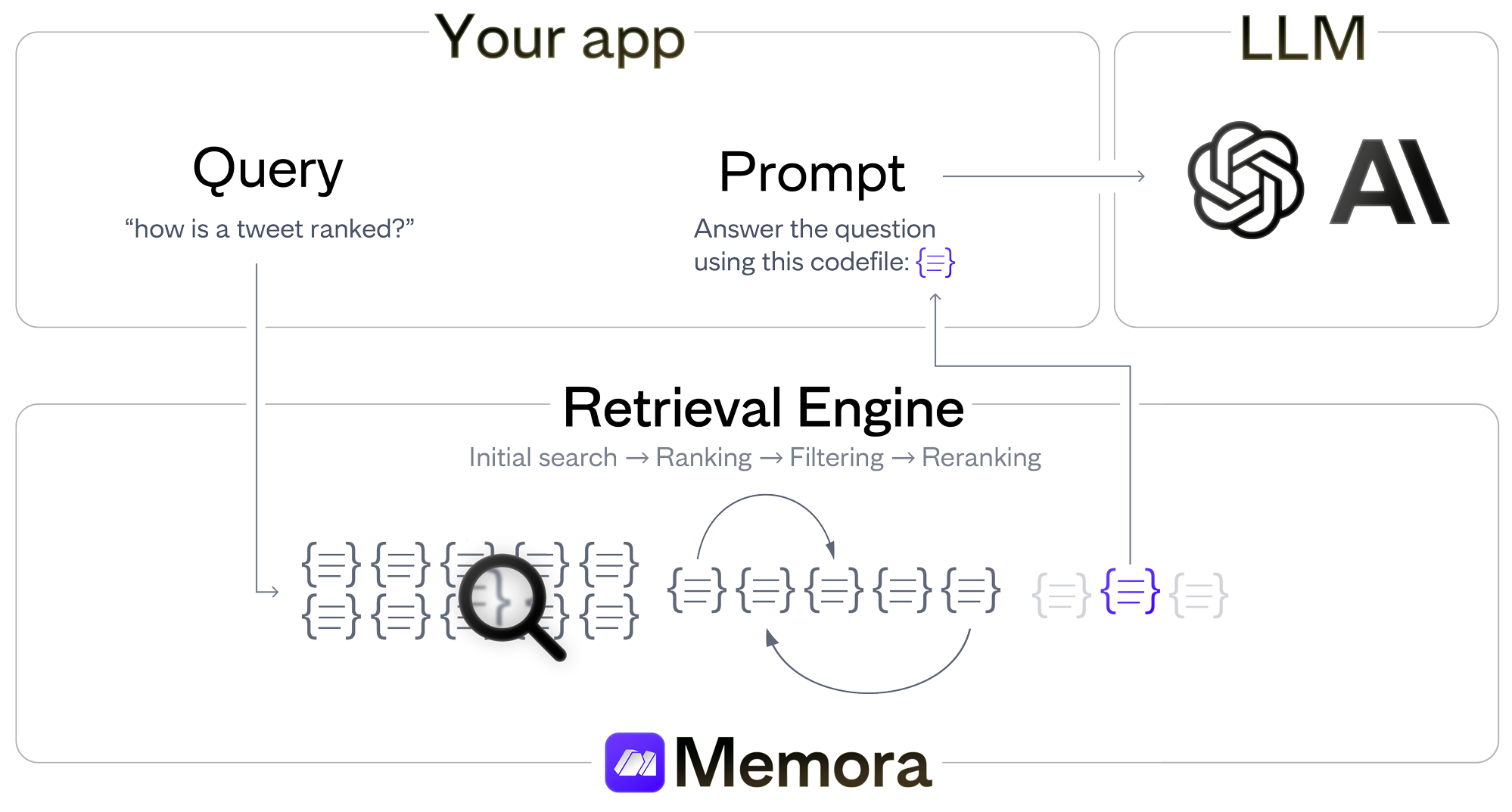
Here's how Memora works internally when you upload a document to it:
- Create an embedding using e5-large, chunking documents when needed.
- Store the embeddings in Weaviate.
Retrieval:
- Retrieve the top 5k candidates via k-nearest-neighbor search in Weaviate.
- Rerank those 5k with ms-marco-MiniLM-L-12-v2.
- Rerank the top 50 again with a version of RankT5 and return the final top-K.
On inference
All of Memora's infra ran on AWS. For model inference we used Inferentia-2 instances, which were cheaper than GPUs while still meeting our latency requirements for this workload.
Javascript/Typescript library design
I also designed and implemented Memora’s JS/TS client. The goal was to make “multi-stage retrieval with metadata filtering” feel as simple as writing a normal, fluent query:
import memora from 'usememora'
memora.auth('your-api-key')
const citations = [
'The Answer to the Ultimate Question of Life, the Universe, and Everything is 42',
'May the Force be with you.'
]
const metadata = [
{ from: 'The Hitchhiker\'s Guide to the Galaxy', year: 1979, genres: ['science fiction', 'humor'] },
{ from: 'Star Wars', year: 1977, genres: ['science fiction'] },
]
// Index documents
await memora
.in('book-citations')
.add(citations)
.metadata(metadata)
.go()
// Query with metadata filters
const docs = await memora
.in('book-citations')
.find('the meaning of life')
.where('genres', 'contains', 'science fiction')
.and('year', '>=', 1978)
.go()
console.log(docs[0])
Design choices:
- Builder pattern: every operation is a chain (
in()→add()/find()→where()/and()→go()), so even complex queries stay readable. - Strongly-typed API: requests, responses, metadata, and filters are all typed in TypeScript.
Outcome
Due to a couple of reasons I won't go into here, I lost conviction that Memora would work as a startup. As a consequence, I left the project a bit after launch. My ex-cofounder ran it for a while, but decided to shut it down sometime in 2024.
Still, as is the case with everything I do, the main reason I decided to work on Memora was for curiosity and in hopes of learning more in the unstructured retrieval space, and through that lens, my time spent on Memora was a major success.